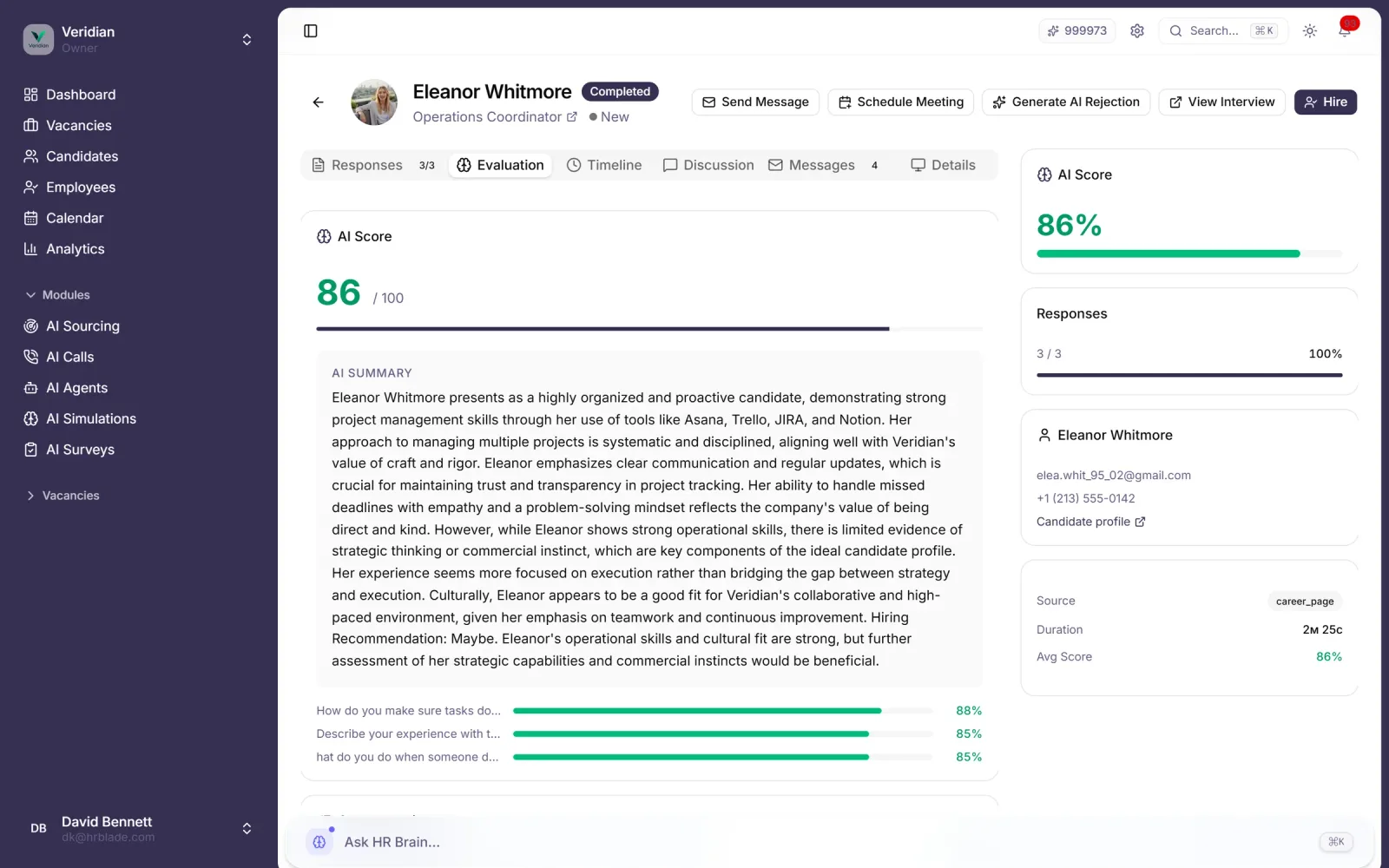
Mehrschichtige Integritäts-Engine flaggt KI-generierten Text, Copy-Paste aus öffentlichen Antworten, verdächtiges Verhalten und outsourcte Submissions — mit 94 % Erkennungsgenauigkeit.
Kostenlose Testphase starten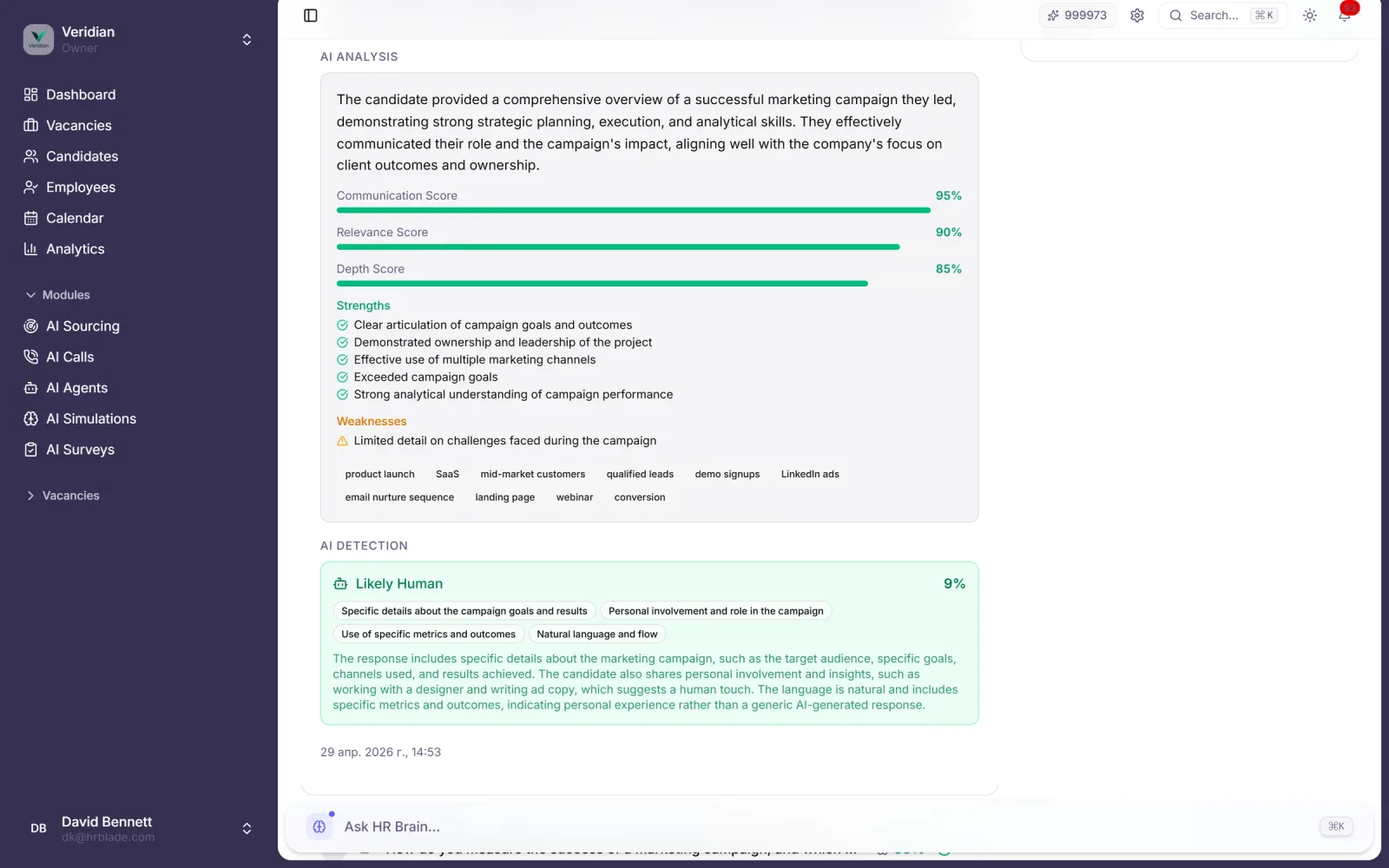
Anti-LLM-Klassifikator markiert Antworten von ChatGPT, Claude oder Gemini in englischen, spanischen und deutschen Submissions.
Tab-Switch-Erkennung in Assessments, Paste-Frequenz-Anomalien, Zeit-pro-Frage-Muster, Edit-Historie-Inspektion.
Jede markierte Antwort enthält das Reasoning, Quellenvergleich und Confidence-Score für die Recruiter-Review.